Is Coveralls down right now?
No — Coveralls is up. All systems operational as of Jul 13, 11:42 PM UTC.
Current Status
All Systems Operational
Components
Recent Incidents
Increased latency for large repos
noneJul 10, 2026 · resolved Jul 13
This incident has been resolved but we believe it triggered a worsened incident overnight Sun night/Mon morning (US PDT) which has just been resolved. To be confirmed by full RCA, we believe a deluge of large repo uploads tied up individual web servers that handle frontline requests. Each web server is able to recover on its own, and did, but as volume increased all servers were eventually affected, only allowing short windows where requests could get through—rejecting most requests with 504 errors. We'll post a post-mortem when we understand more about what happened and how to prevent it going forward.
Increased latency for large repos
noneJul 7, 2026 · resolved Jul 8
Increased latency for large repos has been resolved for the general public. We will be clearing three outlier repos overnight, which should be fully cleared by tomorrow AM.
Increased latency for large projects
noneMay 18, 2026 · resolved May 28
We are closing this incident. Our main background processing queue for larger repos has had no backups in 48 hrs. We will continue monitoring for recurrence.
Unschedule maintenance
noneMay 10, 2026 · resolved May 10
This incident has been resolved.
Service outage (RESTORED, MONITORING)
noneFeb 24, 2026 · resolved Feb 27
# Suspended for Not Paying—While Paying _Latest update: Tuesday, Mar 24_ [This post-mortem is also available as a PDF](https://s3.amazonaws.com/assets.coveralls.io/statuspage/incidents/20260224/postmortem/Coveralls-Post-Mortem-Service-Outage-Feb-2026.pdf). ## Overview On February 24, our hosting provider suspended our account. Our service was down for 68 hours. The stated reason was past-due charges. When we reached our account manager on the day of suspension, he reviewed our account and told us what he saw: an "account restriction" that, in his words, "shouldn't have happened." Bizarrely, his review turned up an internal note claiming we'd made _no payments in six months_. That was demonstrably false and we provided immediate evidence to prove it. We did have an outstanding balance—the product of a billing dispute that took nearly a full year to reach a decision in our favor. But finalizing what we owed required tracking down two credits we couldn't locate. We asked AR one specific question: _where did those two credits go?_ We asked it _six times_. For some reason we still don't understand, they simply stopped responding. We escalated to our account manager, who promised to intervene. Then we heard nothing from anyone. Until we were suspended. Despite providing evidence of our payments, open billing cases, and relentless communication, we waited three days for our service to be restored. When someone finally acted, we were back online within minutes. Three days, and then minutes. Our provider has not explained that gap, or responded to the formal request for answers we submitted more than two weeks ago. Without those answers, what follows is our account. We're sharing everything and letting you judge for yourself. _If what you need most right now is assurance that this won't happen again, and to know what we're doing for affected customers, you can jump ahead to **What We're Doing** and **Making It Right**._ But we'd ask you to read through. On the surface, this looks like a company that didn't pay its bills and got suspended. The full picture tells a different story, and the evidence speaks for itself. ## About Coveralls Coveralls has been providing code coverage analytics for 15 years. We're bootstrapped: no outside funding. Over 225,000 developers use [Coveralls.io](http://Coveralls.io) every day, and roughly 90% of them are open-source contributors who use the service for free. \[1\] We have never experienced an outage like this in our 15-year history. ## The Incident ### What We Were Told About Suspension More than once, over the past year, we asked our account manager directly whether we were at risk of suspension. Each time, the answer was no. He told us suspension was designed to be rare, that it was reserved for accounts that had gone _delinquent_—stopped _paying_, and stopped _communicating_—and that it required his sign-off, _and_ his manager's. He told us he received a regular list of at-risk accounts among those he managed, so he could review them and give feedback before any action was taken. He told us we had _never_ appeared on that list. He said our provider _knew_ we were paying, and _knew_ we were actively communicating, with AR and with him. Based on everything he told us, suspension wasn't just unlikely, it wasn't supposed to be possible. At least not without warning. ### Timeline **Tuesday, Feb 24 — Day 1** 1:45 PM PST: We suddenly lose access to our hosting provider's console. The service is still up, so we assume it's a technical issue. Multiple team members try their credentials. None work. 2:42 PM: We receive our first support request saying, "posting coverage data stopped working", but we don't see it until 2:51 PM due to the next event. 2:45 PM: A team member gets past a login screen and sees a message: "Your account was suspended because of past due charges." We don't believe it. We reach out to our account manager by email, then text, then phone. He confirms an "account restriction" that, based on his review of our account, "shouldn't have happened", and shares that an internal note on our account says, "_Customer has made no payments for 6 months_." 2:51 PM: We see the first support request. 2:52 PM: We open an incident on our status page. At this point, we are still expecting this to be reversed quickly and do not yet disclose the suspension publicly. In hindsight, we should have. ~3:00 PM: While we're on the phone with our account manager, one of us discovers the official suspension notification in our inbox, timestamped 2:03 PM, about 15 minutes after we were first locked out. Our AM asks us to create a new support ticket and promises to escalate. Two hours fly by while we feverishly collect and send evidence of improper suspension. We expect our AM to get this reversed as soon as he gets through to—_someone_. 5:36 PM: No definitive update. Our AM is "still working on it." He tells us the AR team involved is on Eastern time and may be gone for the day. We post that the issue has been identified and a fix is being implemented. We believe this. We are wrong. 7:28 PM: No resolution. Our account manager tells us he continues to escalate but that under the current circumstances, he himself has "limited access" to our account. Still—_should_ be fixed by morning. We update our incident, extend the outage window, and recommend fail-on-error: false for CI workflows. ~9:30 PM: Still no resolution. We check status throughout the night. **Wednesday, Feb 25 — Day 2** 6:45 AM: We text our account manager, surprised service has not been restored. 9:48 AM: First public disclosure — outage originated at our infrastructure provider. We are unable to access our account. 5:56 PM: After a full day working with our provider's account team, we learn more about the restriction. Not a technical failure—infrastructure and data intact. Their team indicates they are working to reverse it, and we expect resolution by morning. **Thursday, Feb 26 — Day 3** 6:53 AM: Still waiting. "We thought this would be resolved by this morning." 5:13 PM: After a full second day of trying to get answers as to why this is happening, and why it hasn't been resolved yet, the picture remains unclear. No ETA. "What appears to have been an automated action, one that no one on their side has taken ownership of causing or fixing." We commit to evaluating backup infrastructure and promise a full post-mortem. **Friday, Feb 27 — Day 4** 7:41 AM: "As we pass milestones in this outage that we never imagined we would see \(and haven't in 15 years of operation\)..." We announce that if not restored by EOD, we will stand up new infrastructure over the weekend. 11:02 AM: Systems begin coming back online. We have not been told what changed. 11:11 AM: Service partially restored. 12:23 PM: After one hour of monitoring, cautiously optimistic that service is fully restored in all regions. **2:30 PM: After two more hours of monitoring, the incident is officially marked resolved. Total outage: approximately three days \(68 hours\) across 4 calendar days.** ## What We Think Happened Here's what we found when we started looking for answers: ### The Note That Wasn't True The first thing we learned about why our account had been suspended was what our account manager told us: there was an internal note from AR that read: > _Customer has made no payments for 6 months._ This was demonstrably false. Here is our payment history for that exact period—September 1, 2025 through February 24, 2026 \(the date of our suspension\): 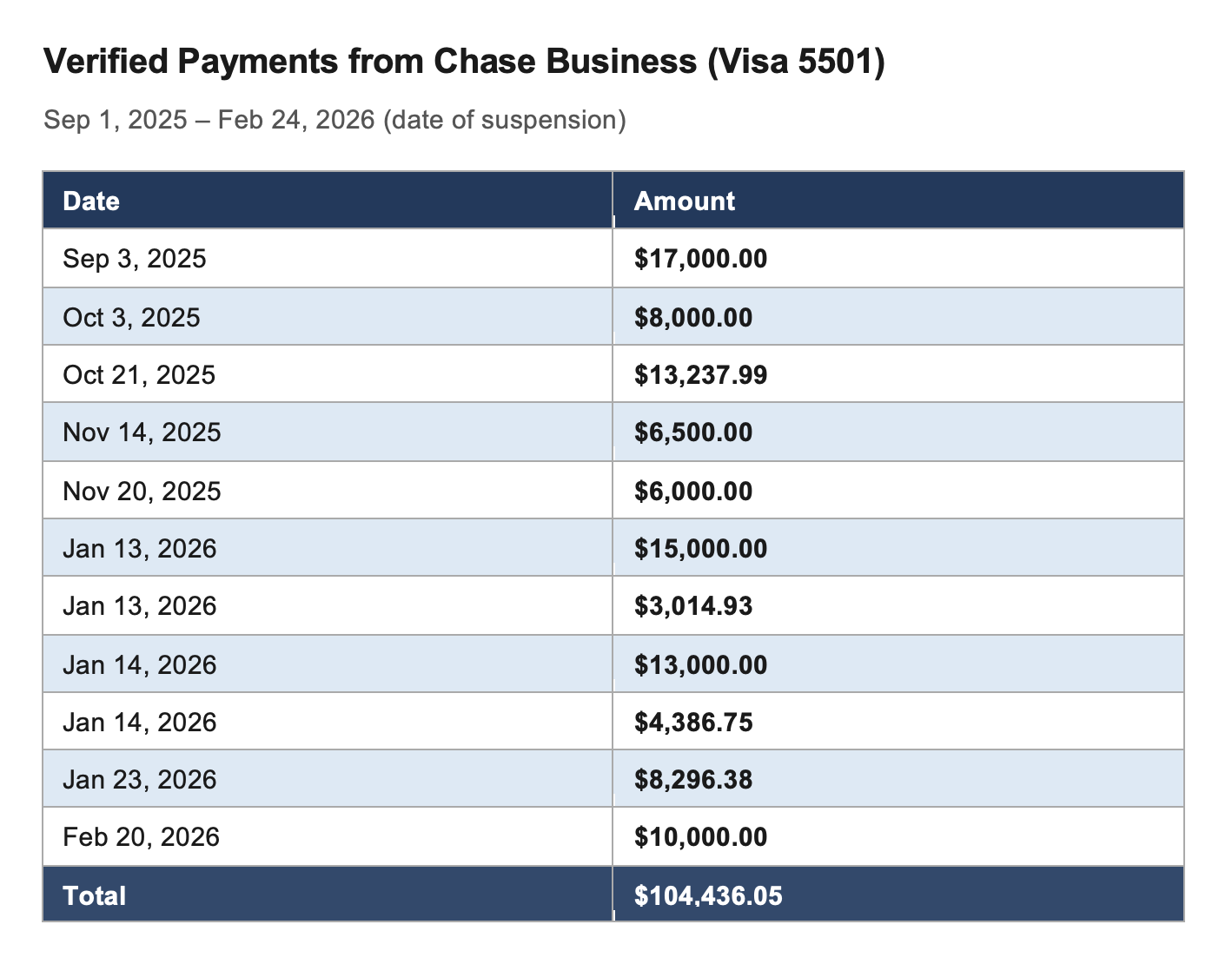 We shared this evidence with our provider immediately, backed by bank statements: 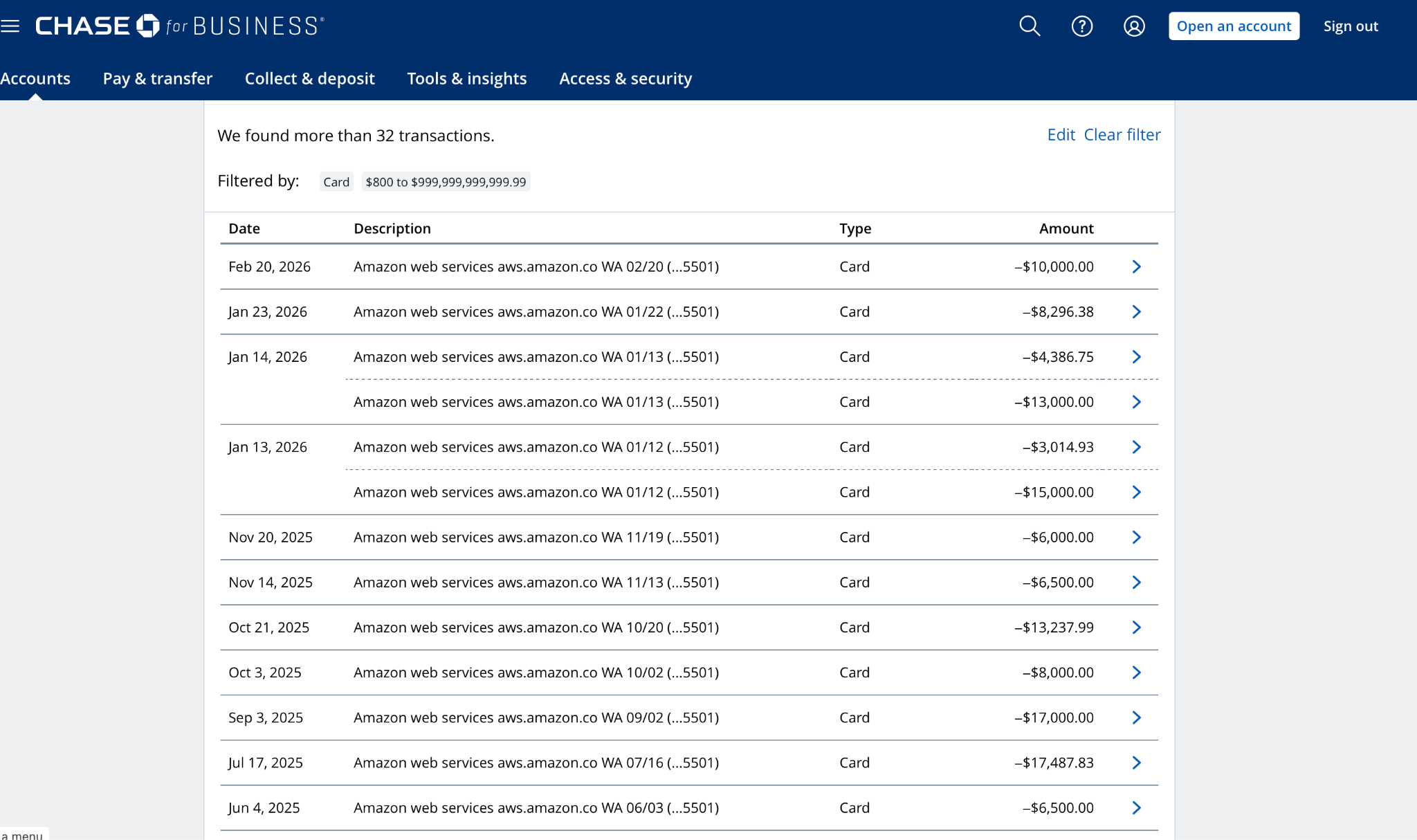 But it raises the question: if we were paying, why would our provider think we _weren't_? ### Why The Note Existed When we look at our billing console we can see why someone might _think_ we hadn't paid: **it shows none of our payments**. Invoices we know to have been fully paid show none of our payments against them. Most notably, the **Transactions Tab** of the **Payments** section of our billing console contains _**no payment records**_ **for last 6 months**—resonating with that internal note: 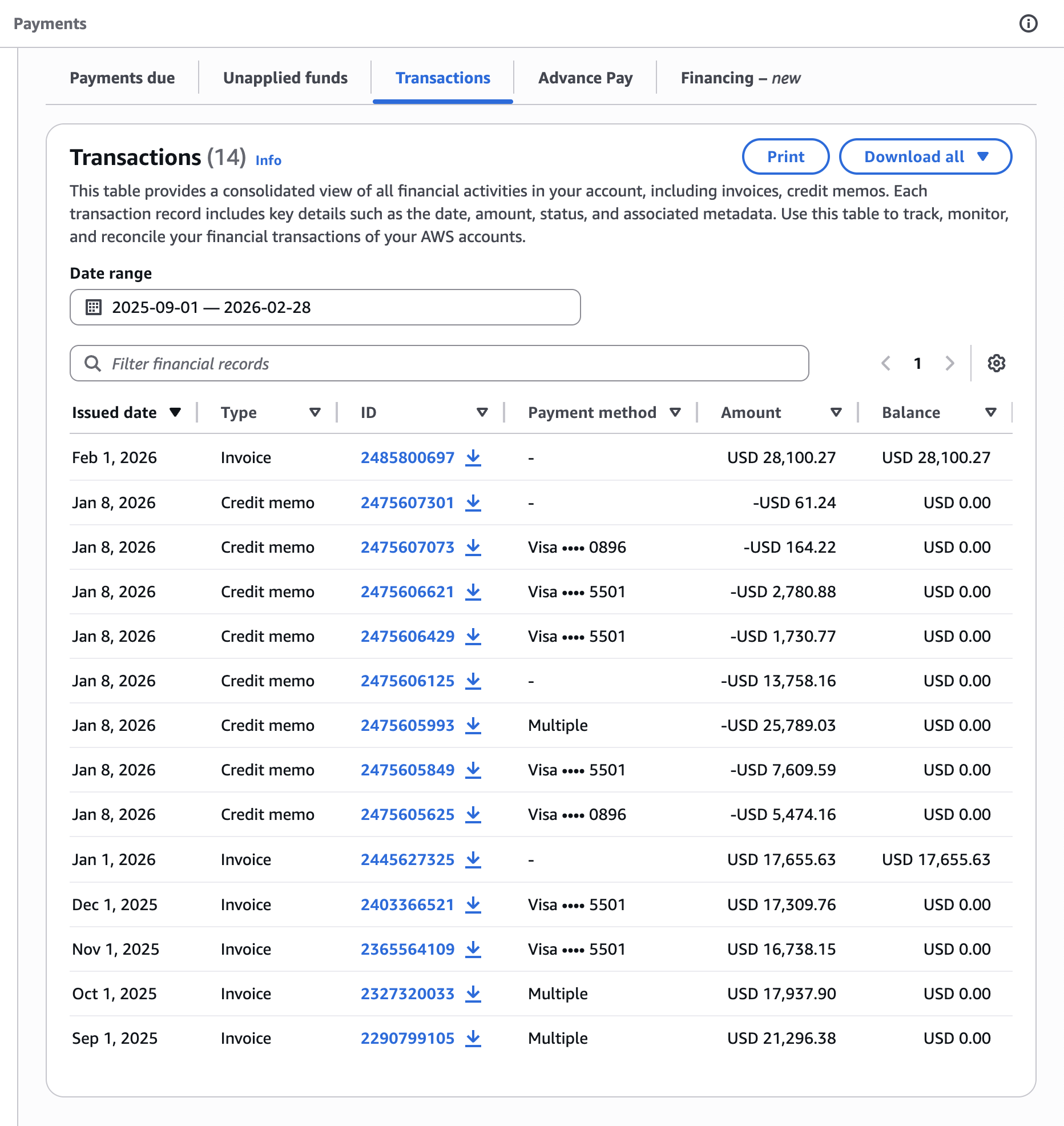 If an automated system relied on this same data to determine whether a customer had made payments, and that data showed six months of silence, it _might_ trigger exactly the kind of suspension we experienced: an automated action with no advance warning, with no one on their side able to explain it or willing to take ownership of it. This is our strongest piece of evidence that the suspension was triggered by bad data, and not our actual account status. — To put this in context: over the six months during which the internal note claimed we'd paid _nothing_, our provider billed us $127,186. Our verified payments for the same period totaled $120,312—a gap of roughly $6,900, which is less than a third of the amount we were actively disputing in our second open billing case. 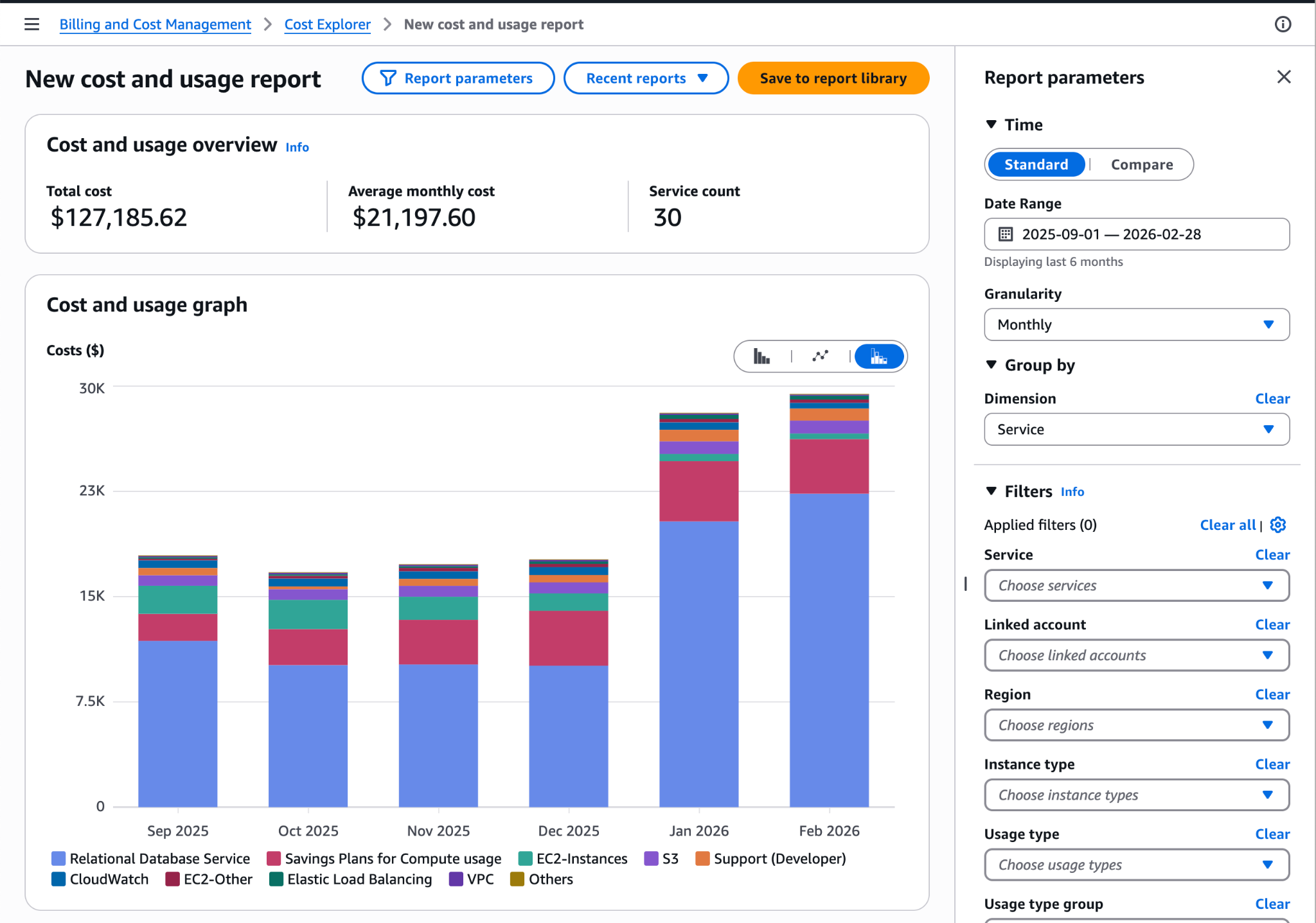 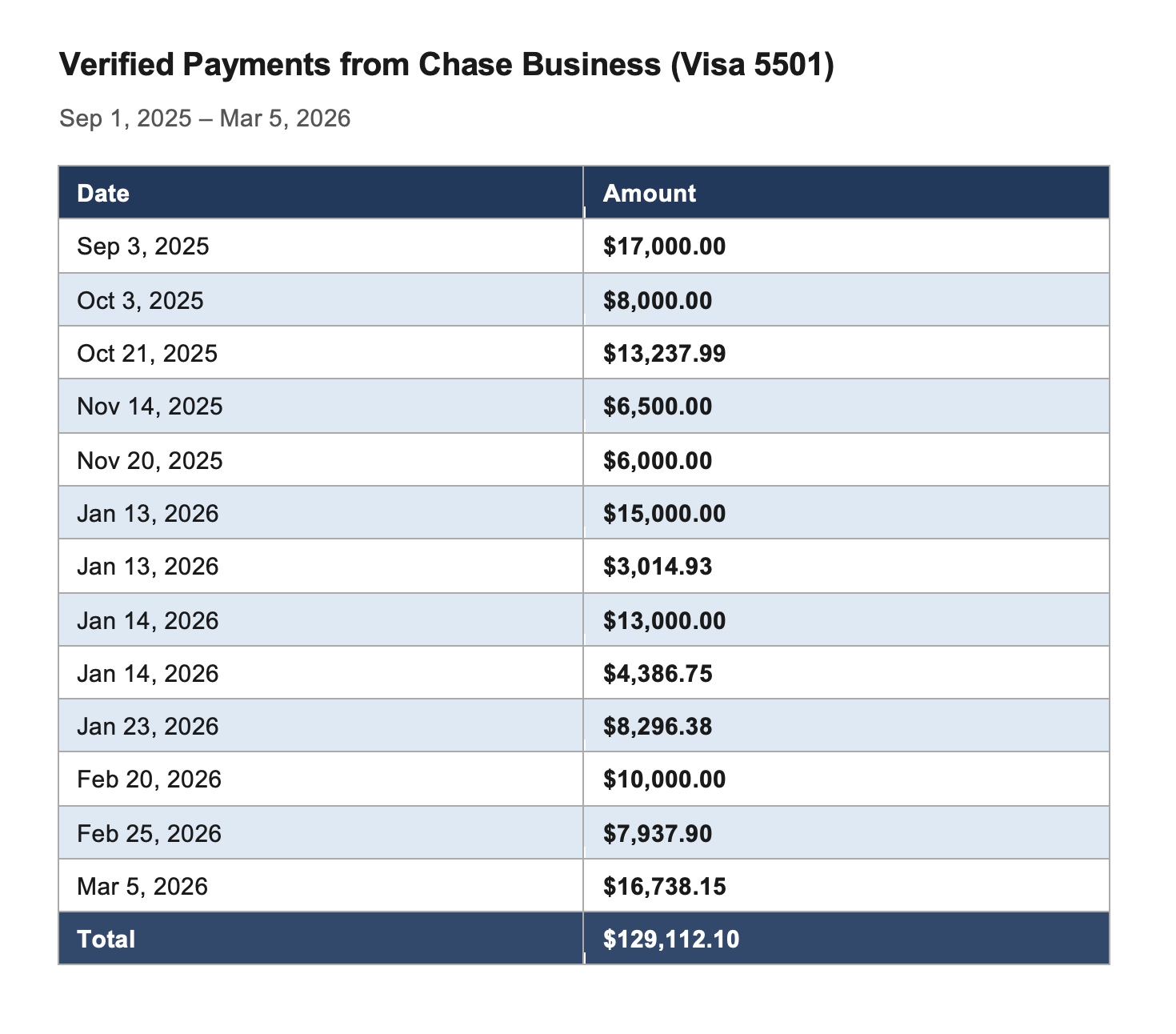 \(By March 5, our payments even exceeded our total invoiced charges for the period: we were not delinquent.\) Our payments were in line with our usage. We weren't _up-to-date_—but the portion of the balance we still carried traced directly back to a single incident that triggered a billing dispute, which took ten months to resolve and still hadn't fully landed by the time we were suspended. — But the note, and the billing console, only explain so much. They might explain how the suspension was _triggered_. They don't explain why it took _three days_ to reverse, even after providing evidence of our payments and open billing cases. If there's an answer for that, it lives in the rest of the story. We've looked. We don't see a justification for either. Draw your own conclusions. ### How The Balance Happened In 2025, we faced a critical infrastructure challenge. Our production PostgreSQL database, approaching a 65TB ceiling due to failing maintenance operations, also needed a major version upgrade before end-of-life. We started the upgrade a month early. It took four-and-a-half months to complete. During three-and-a-half of those months, our provider levied Extended Support Fees on us that roughly _quadrupled_ our database hosting costs for that period. \[2\] We asked our provider to pause or waive them—the fees were simply beyond what we could absorb. They told us that wasn't possible, but that we could open a billing dispute and make our case. We did that, and our provider eventually approved credits for the full amount. But that process took ten months. \[3\] During those ten months, those fees accumulated into a past due balance, so we asked AR for a repayment plan, and their answer was: wait. The credit outcome would affect what we owed, and they needed the case to resolve before we could finalize any repayment agreement. In response to an email titled "Seeking repayment plan for past due balance," an AR representative told us: > _Upon checking, the support case related to billing adjustment review via case ID <redacted> remains active. Please continue to monitor the support case for any update and provide the required information for faster resolution. Once the billing adjustment review for re-appeal was completed, we can discuss for possible payment plan._ In the meantime, we paid what we could and waited for resolution. Our balance stayed on the books for ten months—and with it came past-due notices with threats of suspension we were told were automated and couldn't be stopped. Those are what prompted us to ask our account manager, more than once, whether we were truly at risk of suspension, and his answers gave us confidence that, difficult as the situation was, we were managing it the right way. When those warnings arrived, we did the same thing: made a payment and notified AR. That pattern—always paying, always communicating—put us squarely in the playbook our account manager described, and it seemed to work because we never appeared on his at-risk list. ### A Balance We Couldn't Pin Down When the billing case finally resolved in January 2026, we expected to finalize a repayment plan, but we were blocked _again_—and explaining why requires a brief note on how the approved credits worked: The credits didn't arrive as a direct reduction to our outstanding balance. They came in eight different amounts, apparently as cash refunds—separate transactions that made their way back to us through different payment methods. This meant our balance didn't shrink by the amount of the credits as we expected it would; and, more importantly, some of the credits remained outstanding due to two transactions we couldn't locate. Whether and how _those_ had been applied—_unclear_. Those two missing refunds had no payment method attached in our billing console, and we couldn't find matching deposits in any of our bank or card accounts. They were material to calculating our actual outstanding balance, and any repayment plan, and without AR's help, we couldn't track them down. So we submitted our first request for help on February 12: > _We are having trouble balancing our remaining amount due \($\[redacted\]\) against our credits awarded Jan8 \($\[redacted\]\). Can you help us track down these two \(2\) refund transactions? \[...\] We can't find a payment method associated with those two refunds \[...\] And we can't find matching transactions anywhere in any of our card or bank account statements. Do you know how / where those refunds were applied?_ Three days later, on Feb 15, we received a response that simply restated the information in our billing console. It didn't answer our question. Within an hour of receiving it, we responded and made the stakes explicit: > _Sorry if I wasn't clear: We have not been able to find these two refunds: \[...\] We cannot find the money. We believe we did not actually receive it. We have a general repayment plan in mind that we hope to present, but first we need to resolve this question of these two missing refunds. Without being able to account for that $\[redacted\], we believe our current outstanding balance could be off by that much. Your input on this is crucial for us._ We received no response. Growing concerned about a possible disconnect with AR, that Friday, February 20, we cc'd our account manager on another follow-up to AR and, separately, forwarded the full thread to him directly, asking him to intervene: > _Is there any way you can help us get a response from \[Redacted\] or someone else in Billing regarding the missing refund payments? We want to implement a repayment plan, but need to be clear on our numbers._ He replied the same day: > _Yes — I'll reach out to her. \[...\] Let me pop into the ticket to see if I can escalate._ That was the last we heard from anyone. On February 19, we received a past-due notice with a suspension warning dated the following day. This wasn't unusual—we'd received them throughout the entire ten-month period and had always responded the same way: we made a payment and notified AR. We made a $10,000 payment on February 20 and let AR know. We interpreted the passing of February 20 the way we always had: as confirmation that our payment had been received and the threat had passed. Four days later, we were suspended. ### Six Weeks Before Suspension Six weeks before our suspension, on January 14, we filed a second billing dispute. We had been trying to _reduce_ our hosting costs by shrinking our production database; instead, a mandatory storage configuration upgrade blocked us for 27 days and roughly _doubled_ our costs during that period. We disputed the incremental charges. After working through all required questions, our request was formally submitted to Billing's specialist team: > _Since these charges are not yet present on your account we here at Billing team cannot promise a refund or credits to offset these charges. However, we can connect with your AWS Account Manager for getting an exception approved for you by our specialist internal team. Please contact your Account Manager so they can work with the team for the required approval._ We formally looped in our AM as directed—he was already cc'd on the case, but we followed the process—and he confirmed he was actively monitoring and advocating for our credit request. On January 22, we experienced a temporary account restriction—we were unable to add certain services needed for our workaround. We reached out to our AM and sent a parallel update to our AR contact, informing her of the open billing case and our AM's involvement. The restriction was lifted. Our AR contact replied with direction nearly identical to what we'd received throughout our first billing dispute: > _Kindly continue to monitor the support case for billing adjustment review._ The technical workaround we selected took 20 days—January 22 through February 10—spanning our two most recent billing periods. When the effort was complete, we updated Billing, and our account manager, with the final timeline, cost, and the amount of our credit request. By February 12, everyone had the same information: the work was done, the dispute was submitted, and our last two invoices were under active dispute. Based on prior experience and similar direction from AR, we believed charges under active dispute would not be counted toward our outstanding balance—let alone any balance used to justify suspension. We don't know whether our disputed billing charges _were_ part of the outstanding balance that triggered suspension, or not. All we know is that AR knew about this open case, and so did our AM, who had told us more than once that he reviewed at-risk accounts before any suspension action was taken. Neither warned us that suspension was imminent. — To recap: we were paying—over $100K during the same six months the internal note claimed we'd paid nothing. We were communicating—multiple messages to AR in the twelve days before suspension, plus a direct escalation to our account manager after AR went silent. We had an open billing dispute, and a repayment plan in progress with a specific blocker we had been asking AR to help us resolve for nearly two weeks. None of the criteria our account manager described for suspension applied to us. We hadn't stopped paying. We hadn't stopped communicating. We had never appeared on his at-risk list. The suspension hadn't had his sign-off or his manager's. On the day of our suspension, our account manager reviewed our account and told us it "shouldn't have happened." Three days later, when someone finally acted, service was restored within minutes. To this day, we still don't know exactly why the suspension happened, or why it took three days to reverse. ## Open Questions \(Our Formal Request for Answers\) On March 4, three business days after our service was restored, we sent a formal request for answers to our hosting provider. As of this writing—fourteen days later—we have not received a response. We're not publishing those questions verbatim here because we don't want to frame them as a public ultimatum. But our questions cover four areas: We want to understand what triggered the suspension and who authorized it—whether it was automated or a human decision, and why we were suspended when we had never appeared on our account manager's at-risk list. We want to know why our billing console showed no payment records for a period in which we had paid over $104K in verified bank transactions, and what prompted the internal note. We want to know why our missing refund issue—raised six times between February 12 and February 24—was never substantively addressed before we were suspended. And we want to understand why reinstatement took three days after we provided evidence of our payments, our open billing cases, and our multiple attempts to resolve the blocker to our repayment agreement—especially when service was restored in _minutes_ once someone finally acted. We're committed to updating this post-mortem when we have those answers. ## What We've Learned Two things we should have done differently, and one assumption we should never have made. The process guidance our account manager provided was verbal. We relied on it in good faith—it was specific, consistent, and came from someone with direct knowledge of our account. But we never sought written confirmation. We should have. We noticed discrepancies in our billing console earlier in this process. We flagged them but didn't fully understand their significance, or their potential connection to how our account might be evaluated—until it was too late to escalate effectively. That's a failure we must own. And finally: we assumed we were safe. We were doing everything we'd been told to do. The most recent suspension warning had passed without incident—as others had. We interpreted that silence as confirmation. It wasn't. We should have insisted on written confirmation of our account status; and when we couldn't get AR to respond, we should have escalated beyond email and beyond our account manager. — That's our account of what happened. What follows is what we're doing about it. ## What We're Doing The most significant thing we've done to prevent a recurrence is reduce our monthly database hosting costs by approximately 50% from their peak. We accomplished this by completing a major database project we'd been working toward for over a year—the same project that was blocked twice, producing the unplanned cost spikes at the center of both billing disputes. That pressure is gone. We can easily meet our regular charges going forward. We have nearly paid off our outstanding balance—by 50% if disputed charges are included, by more if not—and we've already begun implementing our repayment plan. We met with our provider this week to formalize that, but we're not waiting to execute. If we prevail in our open billing dispute, the remaining balance shrinks further, making repayment that much easier and faster. We are standing up failover infrastructure on a second provider, expected to be operational within 60 days. No single vendor should ever again have the ability to take our service offline with no recourse. ### Going Forward Going forward, we will not rely on verbal guidance or implicit signals to determine our account standing. We will seek explicit, written confirmation of our status from both our account manager and a dedicated AR contact—someone we hope will commit, in writing, to direct communication \(not system warnings\) that gives us at least one opportunity to resolve any issue before adverse action is taken. We will also get in writing the exact steps our provider follows before suspending an account. Finally, we owe you a commitment about how we communicate during incidents. During this outage, there were moments—particularly on Day 1—where we knew more than we shared publicly. We held back because we didn't fully believe what was happening, and because we kept expecting it to be reversed at any moment. That was the wrong call. Going forward, we will share what we know as soon as we know it, even when it's embarrassing, scary, and we don't yet have the full picture. You deserve that transparency in real time, not just in a post-mortem. ## Making it Right Every paying customer affected by this outage will receive a credit equal to four days of their current subscription—one day for each day of interrupted service. This credit will be applied automatically to your next bill. We understand that's not enough—it's an attempt to be equitable while not harming ourselves more than we've already been harmed by this outage. We want you to know that if anyone feels it doesn't properly compensate for how the outage affected you, just reach out and we will refund the whole month. No questions asked. To our open-source users: the best we can offer is this post-mortem. We know some of you have been through similar things. If it's helpful for you to discuss further, please reach out. We'd also be grateful to hear from anyone who's been through something similar and what you did about it from a hosting perspective. And thanks for the HugOps. We're ready to share some back now. If you have questions about anything in this post-mortem, we're at [[email protected]](mailto:[email protected]). ## Acknowledgments Finally: thank you. During the worst week in our 15-year history, our community showed up. Customers offered server rack space. An SRE director offered to apply pressure through his own provider relationships. People we'd never met sent messages of support and solidarity. In the DevOps community, the term is: HugOps. We received a lot of it that week, and it made a real difference. For those who've stayed with us through this—thank you. We know you have other options. We appreciate the opportunity to make this right. — ## Notes \[1\] _That ratio matters for this case. Our revenue doesn't scale proportionately to our infrastructure costs. Unexpected cost spikes hit us harder than they would a company whose hosting bill is covered by proportional revenue, which is part of why the billing situation at the center of this story developed the way it did._ \[2\] _AWS RDS Extended Support Fees \(ESF\) are charged per vCPU per hour on any RDS instance running a PostgreSQL major version past its end of standard support date — on top of normal instance costs. Our production instance was a db.r6g.16xlarge: 64 vCPUs, 512 GB RAM, at the 65TB maximum RDS storage allocation. At 64 vCPUs and the Year 1 ESF rate, the surcharge approached the cost of the instance itself. Our Major Version Upgrade — which took four and a half months, three and a half of which fell within the Extended Support window — required a Blue/Green Deployment, meaning we ran two db.r6g.16xlarge instances simultaneously for that entire period, each accumulating ESF charges around the clock. Two instances at normal cost plus ESF on both: that is what nearly quadrupled our database hosting costs for the period._ \[3\] _Note: In connection with the credit award, we signed an agreement that restricts us from disclosing specific amounts or characterizing our provider's position on the dispute._ — [Download a PDF version of this post-mortem](https://s3.amazonaws.com/assets.coveralls.io/statuspage/incidents/20260224/postmortem/Coveralls-Post-Mortem-Service-Outage-Feb-2026.pdf).
Get alerted when Coveralls goes down
Alert24 monitors Coveralls and 3,700+ other cloud and SaaS providers. When an outage is detected, it updates your status page automatically and pages your on-call team. No manual updates at 2 AM.
Coveralls status — frequently asked questions
Is Coveralls down right now?
No — Coveralls is up. All systems operational as of Jul 13, 11:42 PM UTC.
What is Coveralls's current status?
Coveralls: All Systems Operational. Alert24 checks Coveralls's status page continuously and can notify you the moment it changes.
How do I get alerted when Coveralls goes down?
Alert24 monitors Coveralls and 3,700+ other cloud and SaaS providers. When an outage is detected it updates your status page automatically and pages your on-call team — no manual checks. Start free at alert24.net.



